对于原始弹幕分类CNN模型进行优化。
修改 word2vec model 的 vector size
- 400: Nice at epoch 38, validation acc 96.56%
- 200: Nice at epoch 37, validation acc 95.22%
- 100: Nice at epoch 34, validation acc 94.78% 单轮训练时间与50维相近,测试样例测试耗时 0.92secs
- 50: Nice at epoch 40, validation acc 94.39% 单轮训练时间在7秒左右,测试样例(av 8365806)测试耗时 0.7secs
尝试加入dropout
在两个 conv 层之间和两个 fc 层之间各加入了一个 \(p=0.5\) 的 dropout
40 epoch 时只有 89.1 acc, 和预想的一样,会导致 达到最佳效果的 epoch 数上升。
用了 dropout 后一个很明显的变化是,原本训练过程中通常是train acc 高于 validation acc,现在通常是 validation acc 高于 train acc,训练后期才基本持平或反超
vector在 epoch 90 左右 达到了96.50%上下的 acc,最终在epoch 300 以上能达到 97.10% 左右的 acc
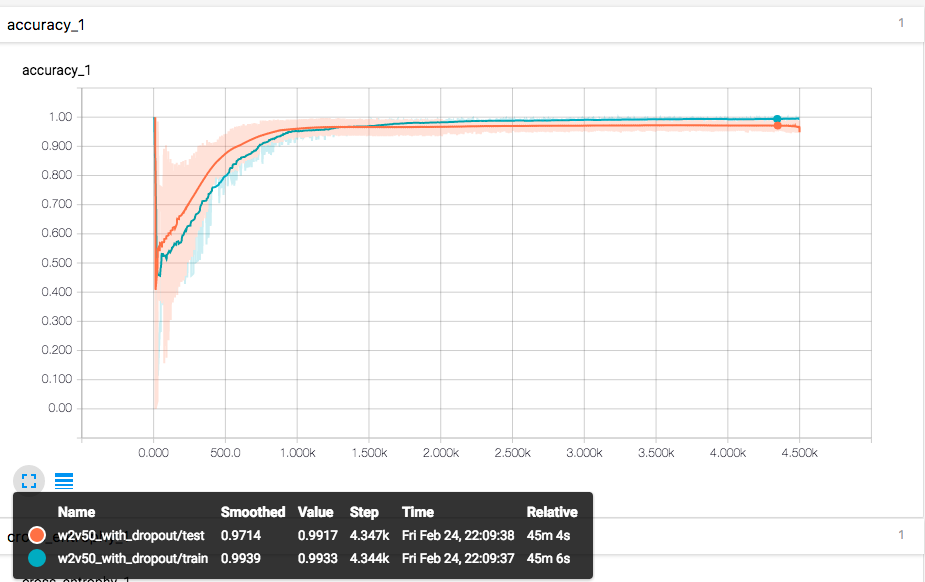
人工检查实际识别效果,仍有少量漏网。果然几个百分点的区别,人简单扫视还是很难看出区别的,而且还要排除安慰剂效应。
实验证明 dropout 确实有效防止了过拟合,并且提高了一定的分类准确度。
接着将几个 word2vec 长度的模型训练图都画出来对比:
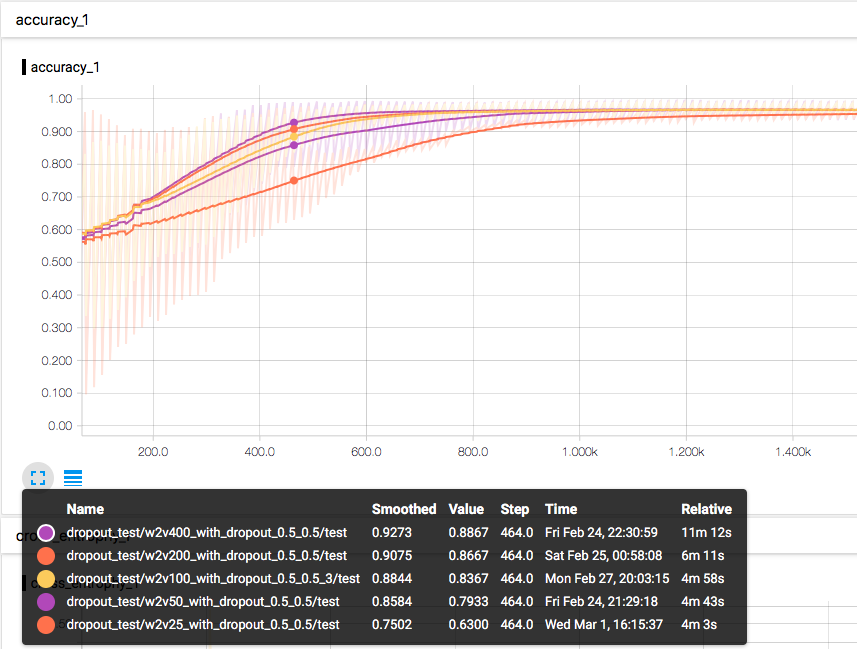
可以从左下角的 tooltip 看到,从上至下分别是词向量长度为 400、200、100、50、25 的模型,在相同迭代次数下的准确度排序。由于选取的是上述模型都仍有收敛空间的迭代数,所以这个排名一定程度上可以代表模型训练所需的迭代次数排序。
由此可以得出结论,词向量维数越多,模型收敛所需的迭代次数越少,但是最终收敛的效果没有变化,这可能是目前训练样本较少的原因。
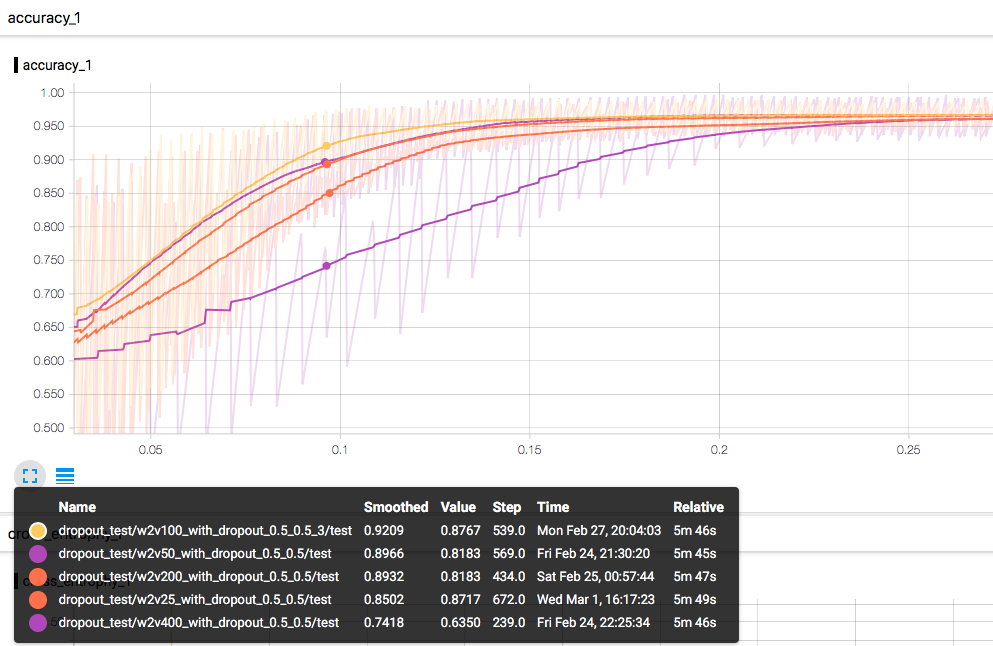
切换到训练时间为横轴的图来看,收敛速度实际上是100维最快,这倒是出乎意外,原本以为会是低维模型最快,结果发现,100维由于单次迭代提升更大,虽然迭代速度稍慢但是总体收敛最快。我还特地检查了100维的data graph,确定的确是在用100维的词向量来训练的。
关于卷积层是否应该加入 dropout 的问题
这个问题我找到了 Reddit 的这个讨论串
里面提到了以下这些说法:
- 卷积层的参数数量没有全连接层那么多,所以不那么需要 regularizaion
- 卷积层 filter map 的梯度是对于整个样本进行平均化的1,这样会使得卷积核原本存在相关性的参数,在样本的不同位置使用了不同的 dropout mask,导致 dropout 无效。当然,你可以想办法使卷积核的 dropout mask 在同一层中固定,但是这又会导致 regularizaion 过强。
- Srivastava/Hinton 在 dropout 的论文中也有提到:在卷积层加入 dropout 的效果等于没有 \((3.02\% \rightarrow 2.55\%)\),因为卷积层的参数太少了,不存在过拟合的问题,所以 dropout 几乎没有效果。但是 dropout 在较低的层仍是有用的,它的效果相当于产生一点噪声,使得后面层数较高的全连接层避免过拟合。
在卷积层使用 dropout 也不是绝对没有的,以下几篇论文中就有用到:
- http://arxiv.org/pdf/1511.07289v3.pdf
- http://torch.ch/blog/2015/07/30/cifar.html
- http://danielnouri.org/notes/2014/12/17/using-convolutional-neural-nets-to-detect-facial-keypoints-tutorial/
但是他们都有卷积层的 dropout 『keep_prob 较大』的特点。
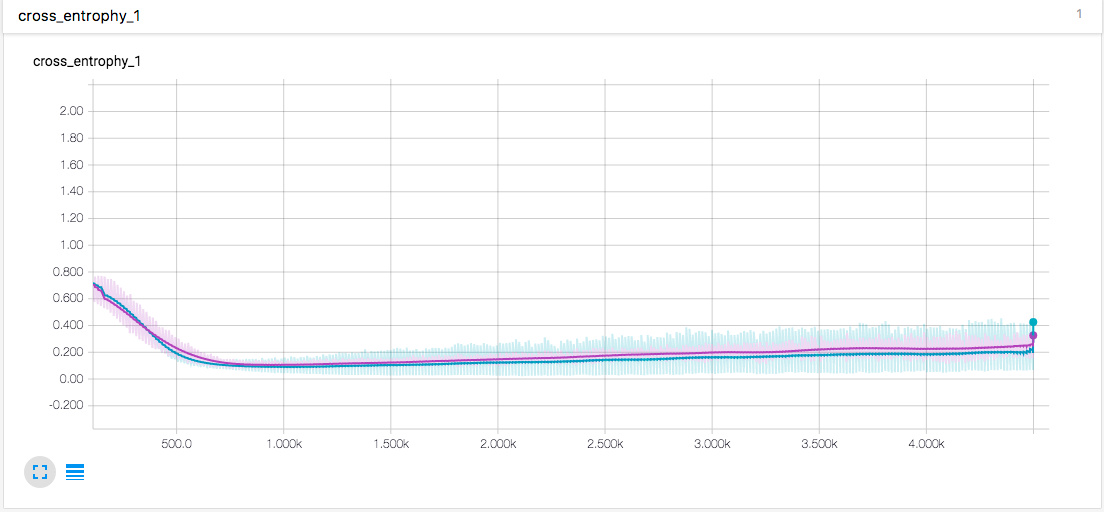
以下是测试的结果:
先测试了卷积层不使用 dropout 的效果
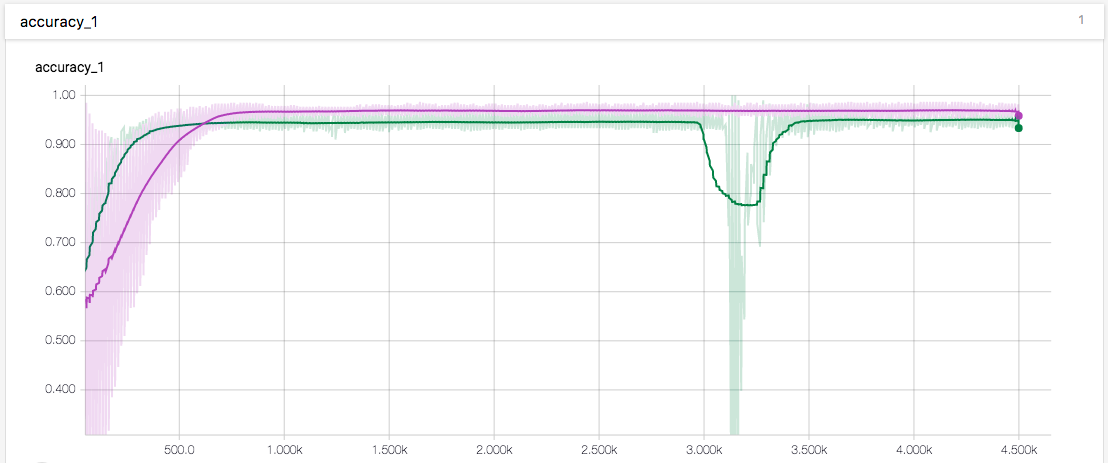
绿线是没有 卷积层dropout 的 acc, 紫线是卷积层 p=0.5 dropout 的 acc,两者都有一个 p=0.5 的全连接 dropout。由此可得卷积层的 dropout 还是有效果的,首先防止过拟合的程度要更高,其次对于准确度的提升也是有的 \((\uparrow2.3\%)\)
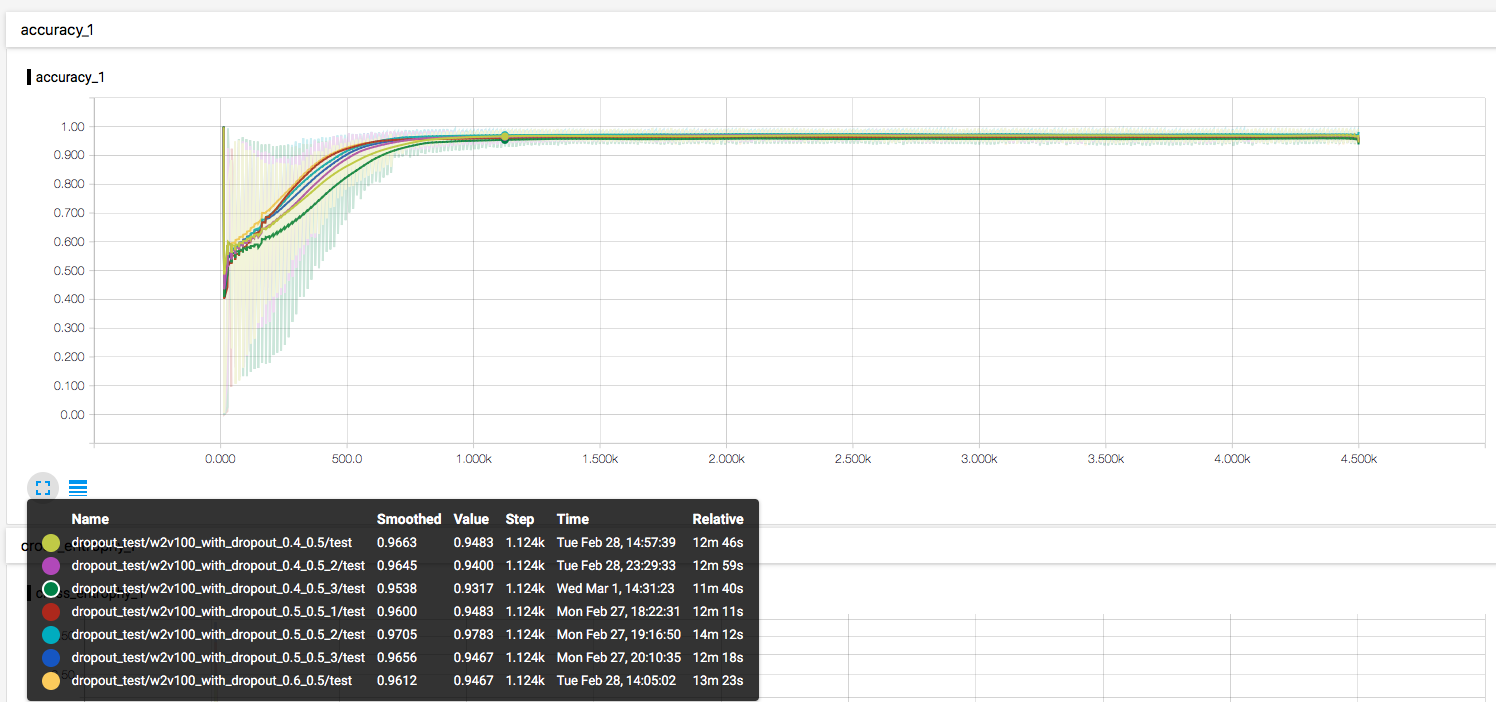
卷积层 p=0.6 和 p=0.4 dropout 的测试,相比 p=0.5 的模型,收敛速度、收敛精度都没有明显的区别。
尝试加入 max_pooling
先在卷积层和全连接层之间加入一个大小为2的 max_pooling1d
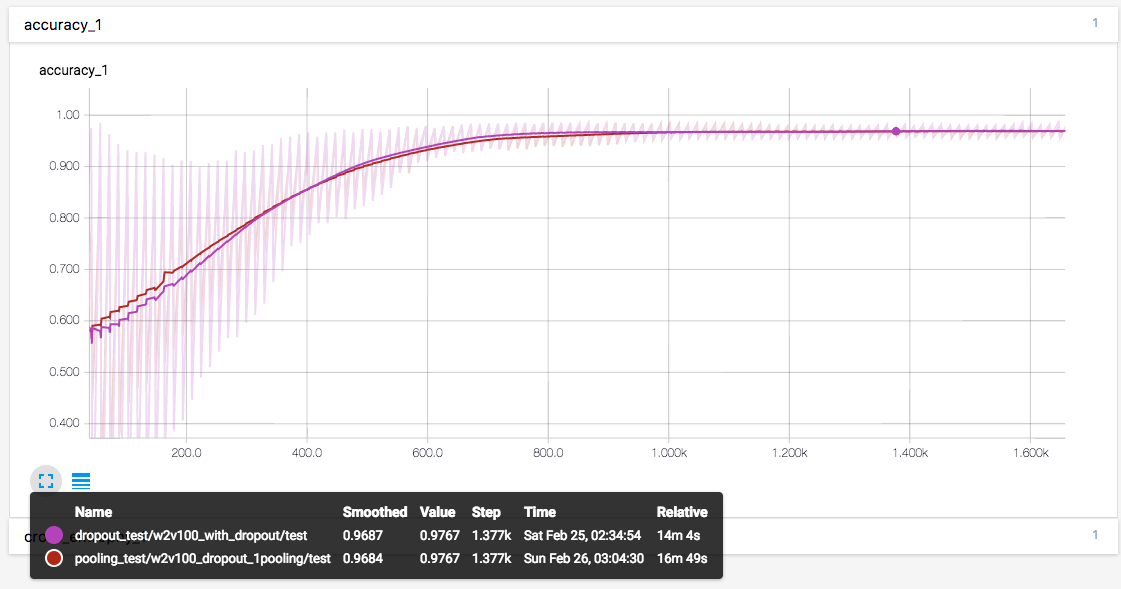
可以看到,这个 max_pool 对于最终收敛精度没有影响,在前期略微加快了收敛,但是中期减慢了收敛。
尝试移动该 pooling 层到两个卷积层之间。
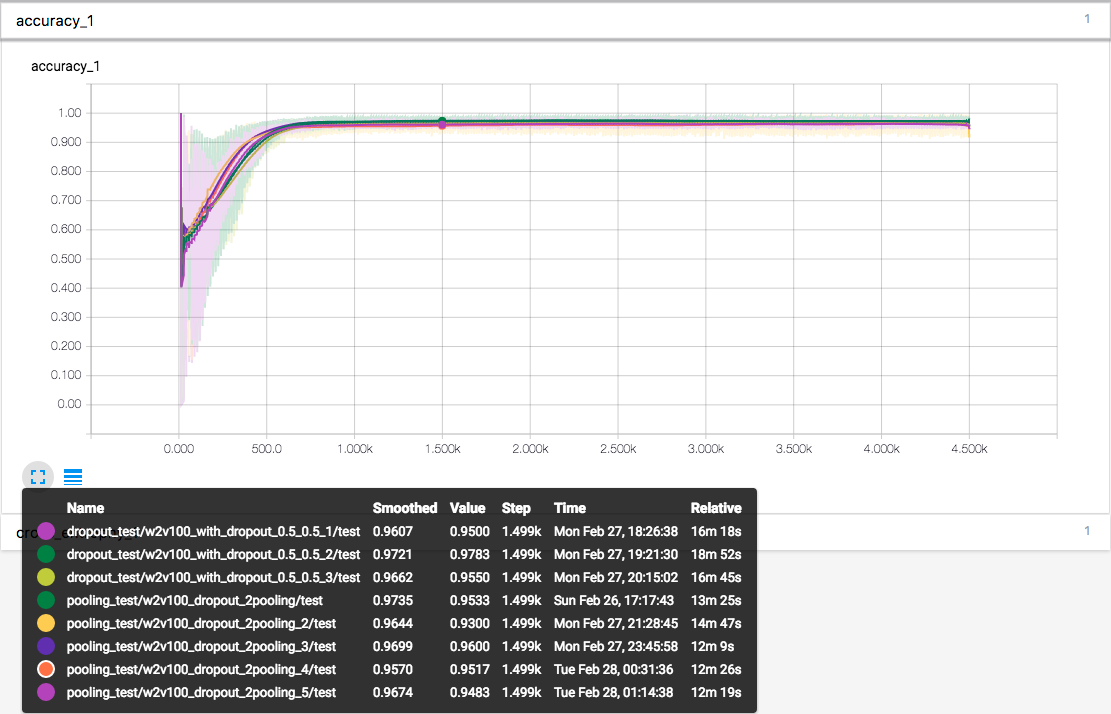
上图为多次测试的结果。收敛速度和收敛准确率没有较为明显的提高或降低 \((96.623\% \rightarrow 96.694\%)\),只有训练速度有略微的提高。
值得一提的是,加入了 max-pool 的模型在高迭代次数的时候,标准差在逐渐增大。我认为这是因为 max-pool 一定程度上降低了训练样本的精度,相当于训练样本变少了,于是乎少量增加了整个模型在高迭代次数过拟合的风险。这里我选择使用84次迭代的模型,也就是图中横坐标约为 1k 的位置。相对来说过拟合的程度应该是非常小的。
-
the gradients are averaged over the spatial extent of the feature maps ↩