整体架构
对于一条弹幕,首先进行分词,然后通过 word2vec 转换为词向量,再填充至固定长度,作为卷积神经网络的输入。
卷积神经网络的结构如下:
model = Sequential()
model.add(Convolution1D(100, 4, border_mode='valid', input_shape=(100, word_model.vector_size)))
model.add(Activation('relu'))
model.add(Convolution1D(100, 4, border_mode='valid', input_shape=(100, word_model.vector_size)))
model.add(Activation('relu'))
model.add(Flatten())
model.add(Dense(100, activation='relu'))
model.add(Dense(2, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
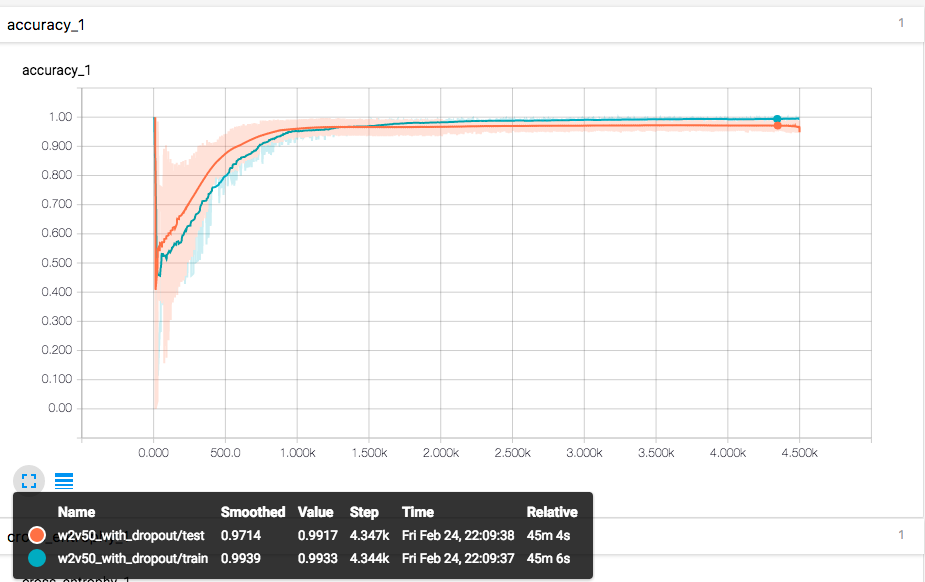
最终输出为2位的 categorical result,直接使用第一项,即骂人弹幕的概率作为输出。
然后通过代理,在弹幕服务器与播放器之间插入一层,实现弹幕的分类与屏蔽。最终实现了有效的骂人弹幕自动屏蔽,但是误伤的情况依然存在。
搭建过程